分析下面的操作:
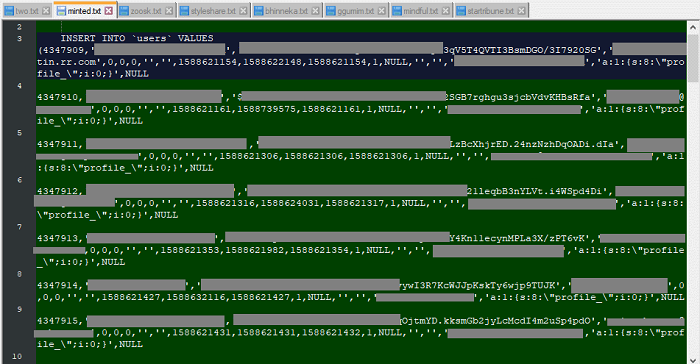
import os from urllib3 import request class file_retrieve(): def __init__(self): self.path = os.path.join(os.path.dirname(os.path.dirname(__file__)),'images') print(self.path) if not os.path.exists(self.path): os.mkdir(self.path) print(self.path) def process_item(self,item,spider): cataory = item['category'] urls = item['urls'] cataory_path = os.path.join(self.path,cataory) if not os.path.exists(cataory_path): os.mkdir(cataory_path) for url in urls: image_name = url.split('_')[-1] request.urlretrieve(url,os.path.join(cataory_path,image_name)) file_retrieve()os.path.dirname(file) 相当于获取当前的文件的本独立路径,如果要获取到本文件的上一层路径就是 os.path.dirname(os.path.dirname(file))
self.path = os.path.join(路径,文件夹名) join就是为了拼接本地的文件夹,最后就是self.path获取到一个完成的文件夹路径 C:/Users/user/PycharmProjectsimages
if not 语句就是为了判断是否为真
os.path.exists(self.path) 是说明这个文件是否存在
os.mkdir(cataory_path) 不存在就创建此文件夹
process_item(self,item,spider): 由于是在类中创建的方法,所以都有self同时在传入冲spider中来的item
image_name = url.split('')[-1] 把url通过_分割出来变成一个list,同时截取最后一位
request.urlretrieve(url,os.path.join(cataory_path,image_name)) urlretrieve 函数是说明下载url中的地址并保存到对应的文件夹中并命令名字。这样可以保证从url下载过来的文件可以放到正确的文件夹中,并保持文件名正确
urlretrieve(url, filename=None, reporthook=None, data=None) 参数filename:指定了保存本地路径(如果参数未指定,urllib会生成一个临时文件保存数据。)
- 版权声明:文章来源于网络采集,版权归原创者所有,均已注明来源,如未注明可能来源未知,如有侵权请联系管理员删除。